The Future of Full Content
by Ben Ubois
The Mercury Parser API, made by Postlight, is shutting down.
Mercury Parser is the service that powers a number of popular features on Feedbin. These include: extracting the full content from partial content feeds, viewing the content of links in Feedbin, and displaying articles that are linked to from tweets.
However, this is actually good news, because Postlight open-sourced Mercury Parser, and it has already improved significantly. Bugs have been fixed, results have become more accurate, and in the case of Feedbin, it is now much faster.
Feedbin has been using the open-source Mercury project since mid-February, but running on different infrastructure. Postlight also open-sourced the AWS lambda API as a separate project, but I had different requirements for authentication, so I created a small web service to handle authentication and run Mercury Parser.
I was pleasantly surprised to see that running the same service on different hardware boosted performance. This isn’t even dedicated hardware like what Feedbin uses for its primary servers. Just a cluster of Digital Ocean virtual private servers.
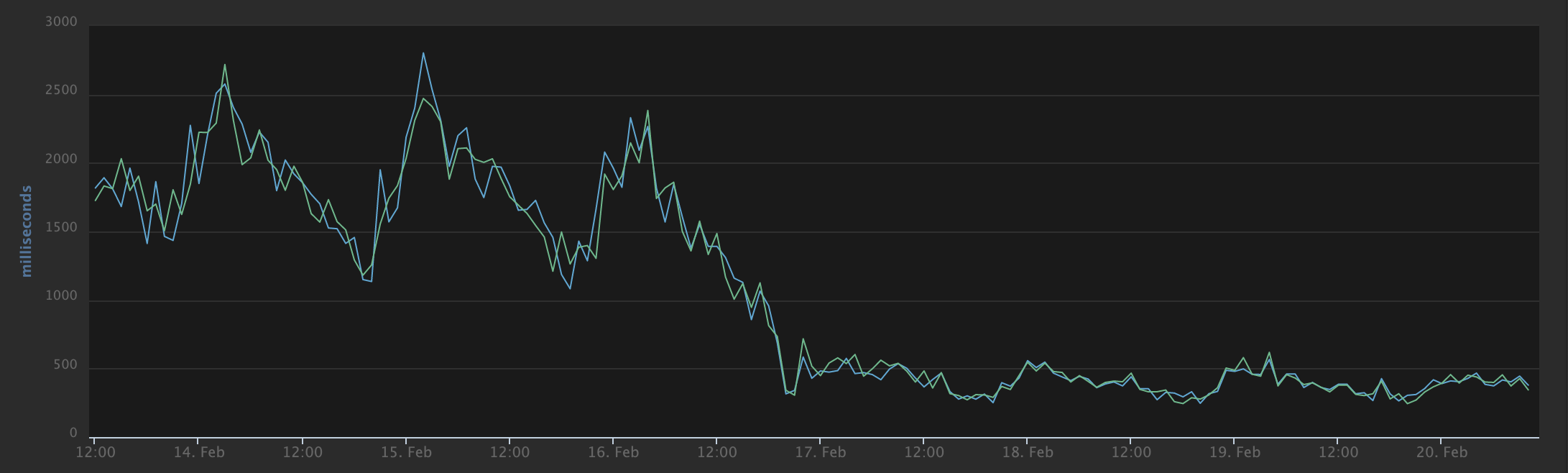
Lambda’s infinite scalability sounds very impressive, but infinite scalability is not a requirement for this use-case. Lambda would probably be cheaper (maybe free?), but I’ll always prefer performance at any cost.
Self-hosting also means that I can open up access to this service to Feedbin customers and app developers.
This service is now being used by Reeder to power its content extraction functionality and I want to offer the same arrangement to anyone that makes an app that supports Feedbin. Please get in touch if you’d like to use it in your app, whether your users are logged in to a Feedbin account or not.
For everyone else, the Feedbin entries API now includes an extracted_content_url key. Visiting this URL will return the extracted content of the entry.
Thanks to Postlight for running Mercury Parser free-of-charge all these years! If you know of a site that could use improved extracted content results, you can contribute a custom parser to the project. It’s a straightforward process if you have CSS and JavaScript experience.
P.S. Feedbin turned six today. Happy birthday! 🎂