10ᵗʰ Anniversary Tee
by Ben Ubois

Feedbin turns ten years old this month! To celebrate there’s a limited edition T-shirt for sale. You can buy it on Cotton Bureau.
It will be available until the end of March.
by Ben Ubois
Feedbin turns ten years old this month! To celebrate there’s a limited edition T-shirt for sale. You can buy it on Cotton Bureau.
It will be available until the end of March.
by Ben Ubois

Feedbin has long supported sending yourself a push notification from an Action. Previously this was available in Safari only. However as of Safari 16, most browsers support the standard Push API, so Feedbin now uses this for notifications. This makes the feature more widely available.
Push notifications can be intrusive, so why support them at all? I think Feedbin is in a unique position to get you exactly the notifications you want. A website that offers notifications will likely send you a notification for everything that is published, but with Feedbin you can narrow this down to a single source or search.
It also enables notifications for any website with an RSS feed, not just the sites that implement notifications.
Here’s how to set it up:

by Ben Ubois
A lot of customers have asked about the future of Twitter support in Feedbin. Even with today’s update there’s still not enough information to make a decision.
Feedbin’s priority is to keep the stuff that you subscribe to up-to-date, so the plan is to continue to use the API. However, it also depends on what the price ends up being:
Finally, it’s unclear to me if Feedbin is even a valid product category according to the new rules. All this does not matter if they decide to revoke Feedbin’s access.
As I write this, Feedbin can’t connect to Twitter’s API. It returns a “Too many requests” error for every attempt. It looks more like a bug based on the other wide-spread Twitter issues from the last few days.
¯\(ツ)/¯
by Ben Ubois
Feedbin now has a Mastodon account, you can find it here: @feedbin@feedbin.social. You can also subscribe right in Feedbin using the new integration.
I was impressed with the set-up experience using the official image in the Digital Ocean Marketplace. Much like a website or email address, you get the most flexibility when you use your own domain for any web presence, and the Mastodon team has made that easy.
by Ben Ubois
Search has been improved at every level, with new features, software, and hardware. Oh, and it’s about 10 times faster.
There’s a nice new way to search within a feed or tag. When you start typing in the search field, Feedbin will suggest sources to search within. Choosing one of these sources will filter the search to only find results within your selection.
When you already have a feed or tag selected in the source column, the search field will be automatically scoped to the selected source.
There’s also a few new fields that you can use to find exactly what you’re looking for.
You’ve long been able to search by the published date, but this field has a new feature: relative dates.
For example, if you want to set up a saved search to see all your unread articles that were published in the last 24 hours, you could use the query: published:>now-1d is:unread. You can also search for a range. For example if you want all unread articles that were published yesterday, this is how: published:[now-2d TO now-1d] is:unread
Next up, link. Link can be used to search for the presence of links to specific domains. To find an article that links the the New York Times you could search for link:nytimes.com. Link is also fully subdomain aware so you could search for link:cooking.nytimes.com. This field supports the ability to search for multiple values, like link:(nytimes.com OR sfchronicle.com)
Feedbin has become omnivorous in terms of the types of content it ingests. To reflect this direction, search has gained the ability to filter by type. These are the types you can search for:
For the podcast and youtube types, there’s another new field: media_duration.
Say you’re as old as I am, and you never want to see a “short” in your YouTube subscriptions. You could create an Action that marks matches to this query as read:
type:youtube media_duration:<120

Check the Search Syntax help page for the full documentation.
To power all of this, the search infrastructure was upgraded as well. Feedbin had been using an ancient version of elasticsearch. This was showing its age with poor performance and flaky reliability. Upgrading to elasticsearch 8 fixed the reliability, but the performance still wasn’t great. The 95th percentile response time for a search was hovering around 1.5 - 3 seconds.
To remedy this, a hardware upgrade was needed. These are the specs for the new search server configuration:
Feedbin’s application servers were upgraded to use Ryzen 5000 series CPUs back in 2021 and I’ve been happy with the performance. They’re clocked higher than most EPYC or Xeon parts and don’t come with the premium price tag or high power requirements. The 5950x comes with 16 cores and 32 threads, so it’s actually great for highly concurrent server configurations, as you’re not giving much up in terms of core count.
Once this new configuration was installed at Feedbin’s datacenter, search performance improved dramatically.

The response time is now consistently under 200 milliseconds.
by Ben Ubois

Feedbin has some new features for your Mastodon reading pleasure.
Mastodon supports RSS. However, RSS auto-discovery has been broken on the latest Mastodon release for some time. To remedy this situation, Feedbin will do some extra work to help determine where the RSS feed is. With this in place, all you have to do to subscribe is enter the URL for a user like mastodon.social/@example.
Next is the format. Mastodon gets the same great treatment as all short and title-less posts in Feedbin, just like Twitter and Micro.blog. The great thing about this is that there’s nothing actually Mastodon-specific here. Any RSS feed can be styled this way.
If a Mastodon post includes a link to a YouTube video or other media, Feedbin will expand the embed right the in the content area. Posts with links will also show the full extracted content and a nice card preview where available.
To round out the support, Feedbin now has the ability to post directly to your Mastodon account, with a new built-in sharing service. It will even pre-fill the post with the title and URL of the currently selected article. You can enable this in the Share & Save section of settings.

by Ben Ubois
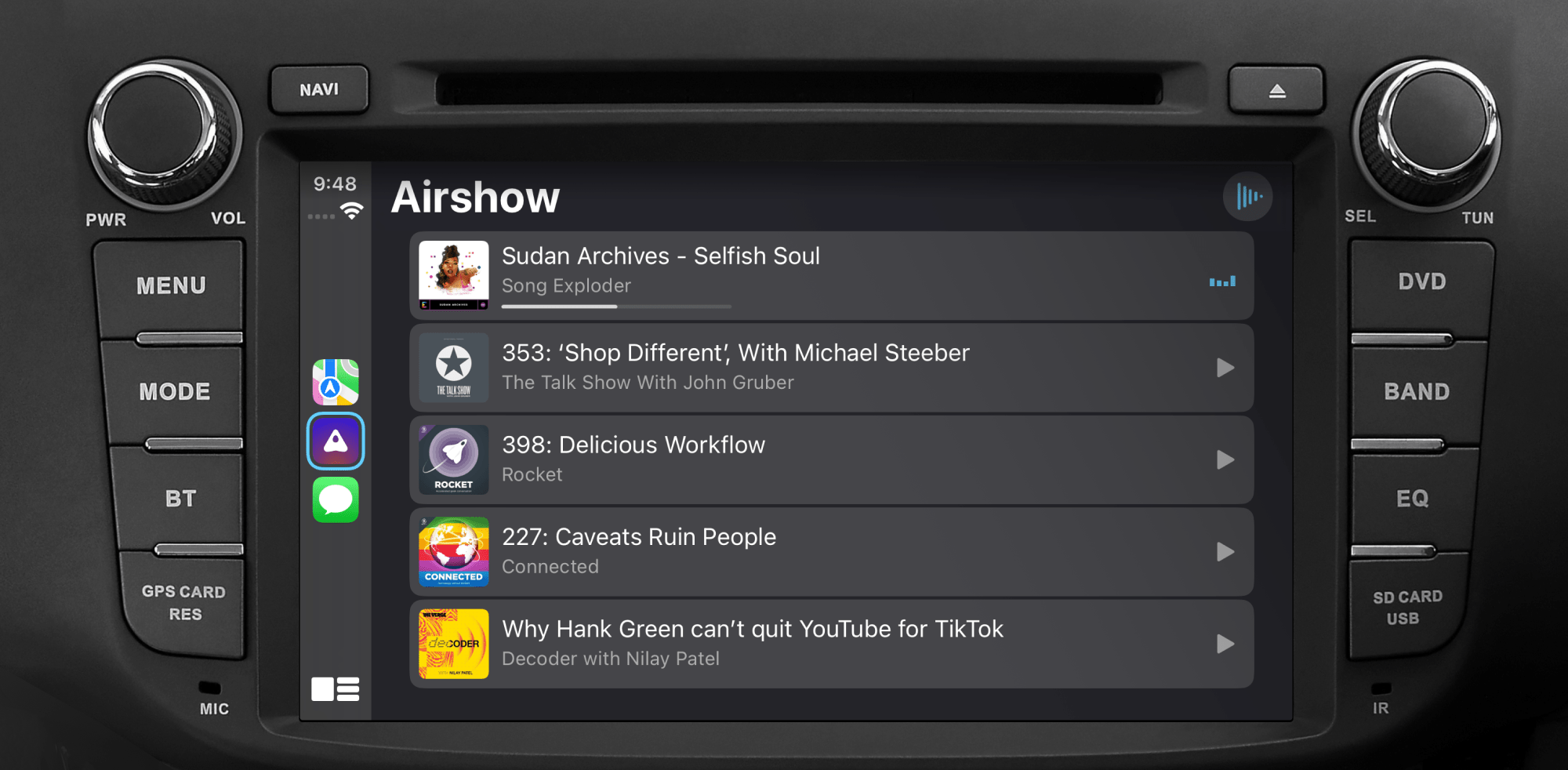
Airshow version 1.2 is out now. The biggest new feature is CarPlay. You can browse your queue and access playback controls.
There’s a number of other improvements and fixes too:
by Ben Ubois

Introducing Airshow. It’s a podcast player for iPhone & iPad. It syncs with the Feedbin account you already have.
Download it now from the App Store.
The idea for the first version is simple: a podcast app that has only the features required to actually listen to and enjoy the shows you love.

There are many great podcast apps out there, so why make another one? Two reasons:
There are two ways I think about podcasts. Entertainment or informational. The design philosophy behind Airshow is to treat podcasts as entertainment where the words, and the space between words are part of the medium. So for now it omits some features you might be used to like speed control or sound effects.
It also takes a lightweight approach to organizing your podcasts. Playlists, folders, etc… provide a lot of flexibility, but they also make it to easy to oversubscribe and bury shows that you subscribe to aspirationally. Instead there’s one place to go to listen: your queue. The idea here is to spend less time managing and just subscribe to shows you actually want to listen to.
New episodes for shows you subscribe to get automatically added to your queue. For podcasts where you only want to listen to the occasional episode, there’s bookmarks. From here you can browse episodes and manually choose what to download.

There are three ways to use Airshow:
This goal for now is to get the basics right and to have a simple, lovable and complete product. Please give it a try if that sounds like something you might enjoy.
by Ben Ubois
The Feedbin for iPhone and iPad app is once again available in the App Store.
Previously, it was ineligible to receive updates until support for Apple’s in-app purchase system was added.
If you’re running the TestFlight version, now is a good time to switch over to the App Store version since it is the most recent release.
Here’s what’s new:
by Ben Ubois

Feedbin is great for following YouTube channels and playlists.
There’s no algorithm or confusion about what you have already watched, just the videos from your favorite creators in chronological order.
To make the experience even better, YouTube embeds have recently been improved.
There’s now rich metadata including the channel name and video length. Profile images are used both at the feed level (instead of the generic YouTube favicon) and in the embed to reinforce the creator.
You can easily subscribe to any YouTube channel, user or playlist by copying and pasting the YouTube URL into Feedbin.